Building an API Gateway from Scratch in Go: Load Balancing, Rate Limiting & Circuit Breakers


Building an API Gateway from Scratch in Go
Load Balancing, Rate Limiting & Circuit Breakers
There's a moment in every backend project where you stop writing individual services and start thinking about what sits in front of them. That layer — the API Gateway — is where a lot of the interesting engineering happens. It's where you handle cross-cutting concerns like traffic distribution, abuse prevention, and fault tolerance, all before a single request ever reaches your application logic.
I wanted to understand that layer deeply, so I built one from scratch in Go. No frameworks. No magic. Just the standard library, a couple of well-chosen packages, and a lot of thinking about why each piece exists.
This is the story of how it came together.
Why Build One from Scratch?
Tools like Kong, AWS API Gateway, or Envoy are battle-tested and production-ready. For most teams, they're the right choice. But using them as a black box means you never fully internalize the tradeoffs involved. I wanted to sit with those tradeoffs myself to understand what a load balancer actually does at the code level, why circuit breakers trip the way they do, and how rate limiting interacts with shared state.
Building it from scratch wasn't about reinventing the wheel. It was about understanding every spoke.
The Architecture at a Glance
Before diving in, here's the high-level picture of how a request flows through the gateway:
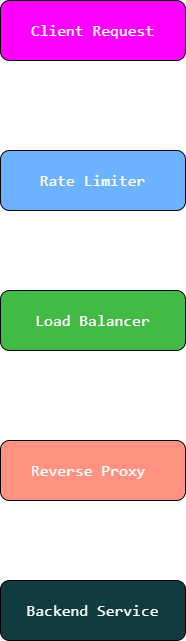
Each layer has one job. Let's go through them one by one.
Layer 1: Round-Robin Load Balancing
The load balancer is the first piece I tackled, and it's deceptively simple on the surface. The core idea: maintain a list of backends, cycle through them in order, and skip any that are down.
func (lb *LoadBalancer) nextBackend() *Backend {
lb.mu.Lock()
defer lb.mu.Unlock()
for i := 0; i < len(lb.backends); i++ {
idx := (lb.current + i) % len(lb.backends)
if lb.backends[idx].IsAlive() {
lb.current = (idx + 1) % len(lb.backends)
return lb.backends[idx]
}
}
return nil
}The interesting part isn't the round-robin logic itself — it's the IsAlive() check. Each backend has an Alive flag protected by an RWMutex. When the reverse proxy reports an error forwarding to a backend, we flip that flag to false:
proxy.ErrorHandler = func(w http.ResponseWriter, r *http.Request, err error) {
backend.SetAlive(false)
http.Error(w, "Bad Gateway", http.StatusBadGateway)
}This is a simple form of passive health checking. We don't poll backends on a schedule — we just learn they're unhealthy when a real request fails. It's lightweight, but it means one user pays the cost of discovering a dead backend. A production system would layer active health checks on top of this. That's a deliberate next step I have in mind.
What I learned here
Concurrency is everywhere in this layer. Multiple goroutines are hitting nextBackend() simultaneously. Getting the mutex scoping right using RLock for reads, Lock for writes was a good reminder that even "simple" shared state requires care.
Layer 2: Rate Limiting with Redis
Next up: preventing any single client from overwhelming the system. The approach I chose is sliding window rate limiting keyed by IP address, with Redis as the shared state store.
func RateLimiterByIP(rdb *redis.Client) func(http.Handler) http.Handler {
return func(next http.Handler) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
ip := getClientIP(r)
key := fmt.Sprintf("rate_limit:%s", ip)
count, err := rdb.Incr(r.Context(), key).Result()
if err != nil {
http.Error(w, "Redis error", http.StatusInternalServerError)
return
}
if count == 1 {
rdb.Expire(r.Context(), key, WindowTime)
}
if count > MaxRequest {
http.Error(w, "Too Many Requests", http.StatusTooManyRequests)
return
}
next.ServeHTTP(w, r)
})
}
}The pattern here is INCR + EXPIRE. On the first request in a window, we set a TTL. Every subsequent request just increments the counter. If the count exceeds the limit (100 requests per minute, by default), we reject with a 429.
One detail I paid attention to: extracting the real client IP. When a gateway sits behind a load balancer or CDN, the actual client IP is usually in the X-Forwarded-For header, not RemoteAddr. The getClientIP function handles that:
func getClientIP(r *http.Request) string {
ip := r.Header.Get("X-Forwarded-For")
if ip != "" {
ips := strings.Split(ip, ",")
return strings.TrimSpace(ips[0])
}
ip, _, _ = net.SplitHostPort(r.RemoteAddr)
return ip
}What I learned here
Writing this as Go middleware a function that returns a function that wraps an http.Handler was a clean way to keep concerns separated. The rate limiter doesn't know anything about load balancing or proxying. It just decides whether to let a request through or not, then hands off to the next layer. This composability is one of the things I find most elegant about Go's HTTP model.
Layer 3: The Circuit Breaker
This was the most intellectually satisfying piece to build. A circuit breaker is a pattern borrowed from electrical engineering: when too many failures pile up, the circuit "opens" and stops sending requests to the failing service entirely. This prevents cascading failures from taking down the whole system.
I used sony/gobreaker rather than rolling my own state machine the library is well-tested and the API is clean. But the configuration decisions were all mine:
st := gobreaker.Settings{
Name: name,
MaxRequests: 3,
Timeout: 10 * time.Second,
ReadyToTrip: func(counts gobreaker.Counts) bool {
failureRatio := float64(counts.TotalFailures) / float64(counts.Requests)
return counts.Requests >= 5 && failureRatio >= 0.6
},
OnStateChange: func(name string, from, to gobreaker.State) {
log.Printf("[CB] %s: %s → %s\n", name, from, to)
},
}Let me break down what each knob does and why I set it where I did:
ReadyToTrip— the circuit opens when at least 5 requests have been made and 60% or more of them failed. The minimum request count prevents the circuit from tripping on a single bad request during low traffic. The 60% threshold gives some breathing room for transient errors without being too lenient.Timeout: 10s— after the circuit opens, it stays open for 10 seconds. Then it moves to a half-open state.MaxRequests: 3— in the half-open state, we allow up to 3 probe requests through. If they succeed, the circuit closes again. If they fail, it opens back up.
Testing the Circuit Breaker
I wrote a small test script that hammers an endpoint guaranteed to return 500:
for range 10 {
_, err := client.Get("https://httpstat.us/500")
log.Println("err:", err)
time.Sleep(500 * time.Millisecond)
}Watching the logs tell the story in real time was satisfying:
err: Get "https://httpstat.us/500": EOF ← closed, counting failures
err: Get "https://httpstat.us/500": EOF ← still counting
...
[CB] testing-service: closed → open ← tripped!
err: circuit breaker is open ← no request sent, instant fail
err: circuit breaker is open ← sameThe circuit opened after the failure ratio crossed the threshold, and from that point on, requests failed immediately without touching the backend. Exactly the behaviour you'd want in production.
What I learned here
The biggest takeaway was about the half-open state. It's the subtlest part of the pattern. You can't just wait and then assume the backend is healthy you need to probe it carefully. The MaxRequests setting is what makes that probing controlled rather than a flood.
Putting It All Together
The main.go is where all the layers connect, and it's deliberately simple:
backends := []*proxy.Backend{
{URL: config.MustParseURL("http://localhost:8081"), Alive: true},
{URL: config.MustParseURL("http://localhost:8082"), Alive: true},
}
loadBalancer := proxy.NewLoadBalancer(backends)
redisClient := config.NewRedisClient()
handler := middleware.RateLimiterByIP(redisClient)(loadBalancer)
http.ListenAndServe(":8080", handler)Four lines to wire up a gateway with load balancing, rate limiting, and (via the proxy layer) circuit breaker protection. The simplicity here is the result of keeping each layer focused on a single responsibility.
What's Next
This project is a foundation, not a finished product. A few directions I'm considering:
Active health checks — right now, backends are only marked unhealthy when a request fails. A background goroutine that periodically pings each backend would catch failures faster and recover more gracefully.
Per-backend circuit breakers in the load balancer — currently the circuit breaker and load balancer operate independently. Integrating them so that a tripped circuit breaker also influences backend selection would make the system more resilient as a whole.
Metrics and observability — exposing request counts, latency, error rates, and circuit breaker state through a /metrics endpoint (Prometheus-compatible) would turn this from a learning project into something you could actually monitor in production.
Final Thoughts
Building an API gateway from scratch forced me to confront questions I'd otherwise hand off to infrastructure: How do you distribute traffic fairly? How do you detect and respond to failures fast? How do you protect downstream services without adding too much latency upstream?
These are the kinds of questions that show up constantly in systems design and the best way I know to internalize the answers is to build the thing yourself, make the tradeoffs explicit, and live with the consequences.
Links
- GitHub Repository
https://github.com/Mhabib34/go-api-gateway